こんにちは。今回はDeep Learningにおいて重要なニューラルネットワークのハイパーパラメータを自動で提案してくれるライブラリ、Optunaについてまとめていきます。これは、スパゲティコードの治療回にて供養が必要となった勉強用プログラムの第一弾です。ソースコードはここに載せています。それでは早速観ていきましょう。
Contents
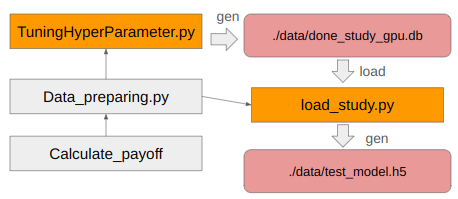
プログラムの概要図
このプログラムは大きく分けて2種類のプログラムから構成されます。一つはニューラルネットワークの構成(ハイパーパラメータ)を決定するプログラム、もう一つはその結果をもとに実際にニューラルネットワークを作成するプログラムです。この2つのプログラムは両方ともデータ生成プログラムをimportしているために、下記の通り構造がやや複雑になっています。
小話
これを実装するにあたり、TuningHyperParameter.pyとload_studyから呼ばれているData_preparing.py、およびそこから呼び出されているCalculate_payoff.pyは2つまとめてlibraryフォルダを用意して分けました。したがってdirectory直下にはTuningHyperparameter.py, load_study.py, dataフォルダ, libraryフォルダしかありません。よって半年ぶりにこのコードを読んだ時も、TuninghyperParameter.pyとload_study.pyの関係さえ思い出せればなんとかプログラム設計を読み解くことができました。でも、上図をREADMEに添付するだけでこんなのはわかるので、いかにドキュメンテーションが大切か思い知らされますね。
TuningHyperParameter.pyの概要
このプログラムの中にはTQNetworkクラス(Tuning Q networkより)が用意されていて、何もなければオブジェクト作成時に下記のrun_study_mainが走るようになっています。
run_study_main()
def run_study_main(self):
study = optuna.create_study(direction="minimize",storage="sqlite:///data/done_study_cpu.db")
study.optimize(self.objective, n_trials=3)
print("Number of finished trials: ", len(study.trials))
print("Best trial:")
trial = study.best_trial
print(" Value: ", trial.value)
print(" Params: ")
for key, value in trial.params.items():
print(" {}: {}".format(key, value))study = optuna.create_study()、study.optimize()の行が一番大切で、そこでハイパーパラメータの探索回数や結果の保存場所を規定しています。それ以外は探索結果のパラメータを表示する部分なので対して重要では無いですが、study.best_trialで各種パラメータが返ってくるのが便利ですね。詳細はoptuna.study.Studyのリファレンスを参照。ちなみに上記プログラム中で出てくるself.objectiveは同クラス内の別の関数を指しています。それが下記です。
objective()
def objective(self,trial):
EPOCHS = 10
N = 500
test_N = 50
inputs, outputs = dp.data_creator(N)
test_inputs,test_outputs = dp.data_creator(test_N)
dataset = tf.data.Dataset.from_tensor_slices((inputs, outputs))
test_dataset = tf.data.Dataset.from_tensor_slices((test_inputs, test_outputs))
# Build model and optimizer.
model = self.create_model(trial)
optimizer = self.create_optimizer(trial)
# Training and validating cycle.
#with tf.device("/cpu:0"):
with tf.device("/GPU:0"):
for _ in range(EPOCHS):
self.learn(model, optimizer, dataset, "train")
mse = self.learn(model, optimizer, test_dataset,"eval")
if mse.result() < self.best_mse:
self.best_mse = mse.result()
# Return last validation accuracy.
return mse.result()これだけ読んでもさっぱりだとは思いますが、最初の7行でデータを作成して、次の2行でモデルとoptimizerの候補を作り、optuna君に学習最適化をしてもらってmodelとoptimizerを最適化するという流れになっていることだけ分かれば良いと思います。このコードを丸コピする場合もdata_creator関数を自分用に改造すれば同じコードで行けるはずです。
create_model()
ここでは実際にニューラルネットワークのレイヤ数をいくつにするか、ノードをいくつにするか、weight_decayをいくつにするかなどを探索できるようにしています。optunaから呼び出される細かい数値は変更可能ですが構成はあまり変える必要はないかなと思っています。
def create_model(self,trial):
# We optimize the numbers of layers, their units and weight decay parameter.
n_layers = trial.suggest_int("n_layers", 1, 3)
weight_decay = trial.suggest_float("weight_decay", 1e-10, 1e-3, log=True)
model = tf.keras.Sequential()
model.add(tf.keras.layers.Flatten())
for i in range(n_layers):
num_hidden = trial.suggest_int("n_units_l{}".format(i), 4, 128, log=True)
model.add(
tf.keras.layers.Dense(
num_hidden,
activation="relu",
kernel_regularizer=tf.keras.regularizers.l2(weight_decay),
)
)
model.add(
tf.keras.layers.Dense(1, kernel_regularizer=tf.keras.regularizers.l2(weight_decay))
)
return modelcreate_optimizer()
optimizerについても探索させることができますが、正直Adamで固定しても良いかなと思っています。このコードを書いたときは探索させる気があったのでcreate_model()と同様の書き方で実装しています。この部分で重要なのはlearning_rateのチューニングです。学習率は低すぎても高すぎてもうまく行かないので、Optunaのような自動探索機に決めてもらえるのは結構嬉しい。
def create_optimizer(self,trial):
# We optimize the choice of optimizers as well as their parameters.
kwargs = {}
optimizer_options = ["RMSprop", "Adam", "SGD"]
optimizer_selected = trial.suggest_categorical("optimizer", optimizer_options)
if optimizer_selected == "RMSprop":
kwargs["learning_rate"] = trial.suggest_float(
"rmsprop_learning_rate", 1e-5, 1e-1, log=True
)
kwargs["weight_decay"] = trial.suggest_float("rmsprop_weight_decay", 0.85, 0.99)
kwargs["momentum"] = trial.suggest_float("rmsprop_momentum", 1e-5, 1e-1, log=True)
elif optimizer_selected == "Adam":
kwargs["learning_rate"] = trial.suggest_float("adam_learning_rate", 1e-5, 1e-1, log=True)
elif optimizer_selected == "SGD":
kwargs["learning_rate"] = trial.suggest_float(
"sgd_opt_learning_rate", 1e-5, 1e-1, log=True
)
kwargs["momentum"] = trial.suggest_float("sgd_opt_momentum", 1e-5, 1e-1, log=True)
optimizer = getattr(tf.optimizers, optimizer_selected)(**kwargs)
return optimizer
load_study.pyの概要
create_model()
load_studyの主要部分であるこの関数、実はTuningHyperParameter.pyのcreate_model()とほぼ同じです。違う点は、探索結果のstudyから最適値をもらってmodelを構成する点です。一応下記にコードを載せて置きます。
def create_model(self):
# We optimize the numbers of layers, their units and weight decay parameter.
n_layers = self.loaded_study.best_params["n_layers"]
weight_decay = self.loaded_study.best_params["weight_decay"]
self.model = tf.keras.Sequential()
self.model.add(tf.keras.layers.Flatten())
for i in range(n_layers):
temp_str = "n_units_l{}".format(i)
num_hidden = self.loaded_study.best_params[temp_str]
self.model.add(
tf.keras.layers.Dense(
num_hidden,
activation="relu",
kernel_regularizer=tf.keras.regularizers.l2(weight_decay),
)
)
self.model.add(
tf.keras.layers.Dense(1, kernel_regularizer=tf.keras.regularizers.l2(weight_decay))
)
optimizer = self.loaded_study.best_params["optimizer"]
loss_fn = tf.keras.losses.MeanSquaredError()
self.model.compile(loss=loss_fn, optimizer=optimizer)
learn_main()
モデルを作ることができたら、それを使って学習を行います。これはごくフツーのmodel.fit()で良いので簡単です。学習が終わったらmodel.save()で保存して終了です。
def learn_main(self):
N = 500
inputs, outputs = dp.data_creator(N)
self.model.fit(inputs,outputs,epochs = 10)
self.model.save("./data/test_model.h5")まとめ
スパゲティコード供養第一弾ということで、Optunaの使い方と応用を紹介させていただきました。自分のコードの稚拙さや改善ポイントの多さに気付かされますね。俺・・頭痛が治ったら、もっとちゃんとドキュメンテーションしながらプログラムを組むんだ・・(強い決意)。ということで、千里の道も一歩から。次回もお楽しみに。