2020年8月某日
こんにちは。最近仕事にばっかり注力していたRockinWoolです。仕事辞めたいといつも思っているのに、それが人生の時間で一番大きな割合を占めているのがしょっちゅう許せないですよね。そういうわけで、前回の投稿から現在までの間で色々勉強のスタイルを模索して、結果としては出社前に一時間程度勉強してから出勤するのがアタマが冴えてベストという答えになりました。これを習慣付けて、パワーパーソンになるべく修練を積んでいこうと思ってます。
さて、今回は前回までの’Pythonで学ぶネットワーク’ではなく、最近にわかに話題らしいGinzaについてです。「まえがきで散々勉強勉強言って置きながら全然アンタの専門ちゃうやんけ」って言われそうですが、やりたかったんだもん。仕方ない。
Ginzaについては次のサイトに詳しく書いてあります。
自然言語処理ライブラリGiNZAをインストールして簡単に動かすまでの手順 そもそも自分がGinzaについて知ったのは完全に偶然です。先週、自分の部署に初めてとなる後輩新入社員がやってきたので、最近興味あることを聞いてみたらIBMのWatsonって答えたんですよね(本当はこの回答は3番目くらいに飛び出した内容で、ドローンとかそういうやつのほうが興味ありそうでしたけど)それでWatsonに興味を持ったんですけど、WatosonはIBMの登録がいるとかなんとかで、なんか面倒だなあって思ってしまったんですよね。それで、来たようなやつで自由に使えそうなやつ無いかなあと思っていたらGinzaにたどり着いたってわけなんです。GinzaはMITライセンスらしいので安全ですね!(ライセンスについては全然知らない)
それでは今回も実況しながら進めて行こうと思います。
まず、Ginzaはpipしか対応していないっぽいので(conda install Ginzaってやったけどダメだった)新たにAnacondaの環境を作成することにします。詳しいことはこのページでも見れば良いと思います。環境名はGinzaを実行する用としてGinpyにしました。
conda create -n Ginpy python=3.8
一応、環境一覧をinfo -eで確認してから、Ginpyに移動します。
conda info -e
conda activate Ginpy
ではGinpyにGiNZAを入れていこうと思います。コマンドは以下の通りにしました。
pip install -U ginza
とりあえず、これでGiNZA自体を入手することは成功したので、所有欲の半分は満たされました。次は支配欲を満たすために実際に使っていくことにします。 まずは形態素解析から。形態素解析は説明するよりも見るほうが早いと思うので説明は省きますが、高校時代にこれがあればもうちょっと国語に興味が持てたかなあと思います(多分そんなことは無い)
適当な作業ディレクトリに移動して以下の流れでファイルを作って、コードを書いてみます。\
mkdir Gintes
cd Gintes
import spacy
nlp = spacy.load('ja_ginza')
doc = nlp('なんかワーカホリックな人からフォロリク来ている。自分のリアル知り合い以外フォロリクされたことないから不安だ。')
for sent in doc.sents:
for token in sent:
info = [
token.i, # トークン番号
token.orth_, # テキスト
token._.reading, # 読みカナ
token.lemma_, # 基本形
token.pos_, # 品詞
token.tag_, # 品詞詳細
token._.inf # 活用情報
]
print(info)
すると、上手く動きはするのですが、警告が!
UserWarning: [W031] Model 'ja_ginza' (3.1.0) requires spaCy v2.2 and is incompatible with the current spaCy version (2.3.0). This may lead to unexpected results or runtime errors. To resolve this, download a newer compatible model or retrain your custom model with the current spaCy version. For more details and available updates, run: python -m spacy validate
ぱっと見、バージョンが新しいから危ないよ。コマンドを打って調整してね!って書いてありそう(適当)なので、コマンドを打ってみる…が全然ダメだし、もう普通に動いているから問題ないやってことで進めていきます(諦め)
先程のGintes1.pyを実行すると以下のような表示が出力されます。
[0, 'なん', 'ナン', '何', 'PRON', '代名詞', '*,*']
[1, 'か', 'カ', 'か', 'ADP', '助詞-副助詞', '*,*']
[2, 'ワーカホリック', 'ワーカホリック', 'ワーカホリック', 'NOUN', '名詞-普通名詞-一般', '*,*']
[3, 'な', 'ナ', 'だ', 'AUX', '助動詞', '助動詞-ダ,連体形-一般']
[4, '人', 'ヒト', '人', 'NOUN', '名詞-普通名詞-一般', '*,*']
[5, 'から', 'カラ', 'から', 'ADP', '助詞-格助詞', '*,*']
[6, 'フォロリク', '', 'フォロリク', 'NOUN', '名詞-普通名詞-一般', '*,*']
[7, '来', 'キ', '来る', 'VERB', '動詞-非自立可能', 'カ行変格,連用形-一般']
[8, 'て', 'テ', 'て', 'SCONJ', '助詞-接続助詞', '*,*']
[9, 'いる', 'イル', '居る', 'AUX', '動詞-非自立可能', '上一段-ア行,終止形-一般']
[10, '。', '。', '。', 'PUNCT', '補助記号-句点', '*,*']
[11, '自分', 'ジブン', '自分', 'NOUN', '名詞-普通名詞-一般', '*,*']
[12, 'の', 'ノ', 'の', 'ADP', '助詞-格助詞', '*,*']
[13, 'リアル', 'リアル', 'リアル', 'NOUN', '名詞-普通名詞-形状詞可能', '*,*']
[14, '知り合い', 'シリアイ', '知り合い', 'NOUN', '名詞-普通名詞-一般', '*,*']
[15, '以外', 'イガイ', '以外', 'ADV', '名詞-普通名詞-副詞可能', '*,*']
[16, 'フォロリク', '', 'フォロリク', 'VERB', '名詞-普通名詞-一般', '*,*']
[17, 'さ', 'サ', '為る', 'AUX', '動詞-非自立可能', 'サ行変格,未然形-サ']
[18, 'れ', 'レ', 'れる', 'AUX', '助動詞', '助動詞-レル,連用形-一般']
[19, 'た', 'タ', 'た', 'AUX', '助動詞', '助動詞-タ,連体形-一般']
[20, 'こと', 'コト', 'こと', 'NOUN', '名詞-普通名詞-一般', '*,*']
[21, 'ない', 'ナイ', '無い', 'ADJ', '形容詞-非自立可能', '形容詞,終止形-一般']
[22, 'から', 'カラ', 'から', 'CCONJ', '助詞-接続助詞', '*,*']
[23, '不安', 'フアン', '不安', 'ADJ', '名詞-普通名詞-形状詞可能', '*,*']
[24, 'だ', 'ダ', 'だ', 'AUX', '助動詞', '助動詞-ダ,終止形-一般']
[25, '。', '。', '。', 'PUNCT', '補助記号-句点', '*,*']
ここで一言、すげえと出てしまいました。ワーカホリックとかも辞書登録されているのでしょうか?かなり正確に結果が出ていることがわかります。これらの関係は画面出力でより簡単に理解できるみたいです。
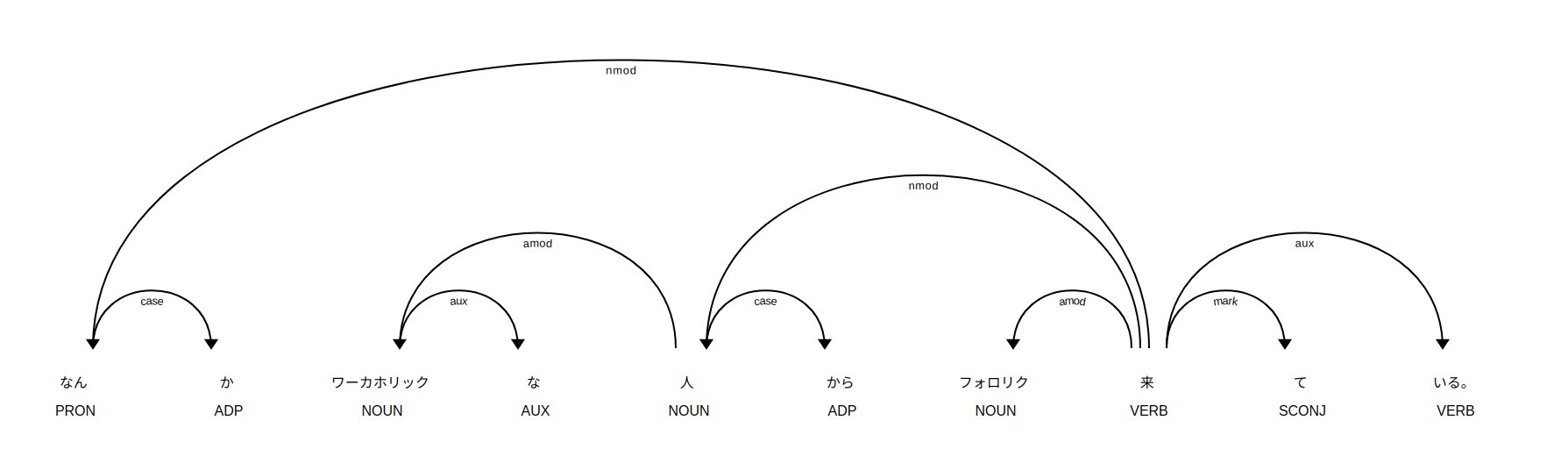
import spacy
from spacy import displacy
nlp = spacy.load('ja_ginza')
doc = nlp('なんかワーカホリックな人からフォロリク来ている。自分のリアル知り合い以外フォロリクされたことないから不安だ。')
displacy.serve(doc, style="dep")
あと個人的に気になったのは2つの文章を見比べて類似度とやらを出してくれる機能。具体的に何をやっているのかは専門家ではないので知らなくていいかなあ。
import spacy
nlp = spacy.load('ja_ginza_nopn')
doc1 = nlp("このパソコンは現在シミュレーションを実行中です")
doc2 = nlp("最近、雨が多すぎやしませんか?")
similarity = doc1.similarity(doc2)
print(similarity)
上を実行すると結果は0.46384519507135974って表示されます。半分くらい似ている・・・らしいけど、なにが半分似ているって根拠なんだろう?
文章の中の各言葉間の類似度を計算することもできるらしいです。
import spacy
import numpy as np
import pandas as pd
nlp = spacy.load('ja_ginza')
tokens = nlp('お米食べろ!')
token_size =len(tokens)
tokens_array = np.zeros((token_size,token_size))
for i in range(token_size):
for j in range(token_size):
tokens_array[i][j] = tokens[i].similarity(tokens[j])
df_tokens = pd.DataFrame(tokens_array)
df_tokens.columns= tokens
df_tokens.index = tokens
print(df_tokens)
ここで問題発生。最初に作ったAnacondaの環境にはpandasが入ってなかったようなので、急遽conda install pandasで追加しました。
最終的には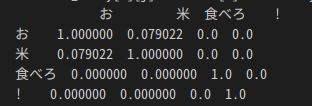 が出力されて単語ごとの類似度もわかります。すごいですねえ。
が出力されて単語ごとの類似度もわかります。すごいですねえ。